
Feature Flags for AI Features Are Broken If You're Using Them Like Traditional Flags
A 5% canary rollout of your new AI summarization feature comes back clean. Engagement is up, no spike in support tickets, error rates look normal. You push to 25%, then 50%, then full release. Three weeks later, a customer emails your support team with a screenshot: your AI confidently summarized a contract as containing a termination clause that doesn't exist.
This isn't a hypothetical. It's the failure mode that traditional feature flags are structurally blind to — and it's happening at teams that are otherwise rigorous about deployment practices.
The problem isn't the tooling. LaunchDarkly, Unleash, Flagsmith — these are solid platforms. The problem is that the mental model behind feature flags was built for deterministic software, where the same input reliably produces the same output. LLMs are the opposite of that. When you roll out an LLM-powered feature to 10% of users, you're not controlling one variable. You're releasing a system whose behavior varies across every single request, influenced by token sampling, context window contents, and model version drift. User cohort data will tell you whether people clicked. It won't tell you whether the model is hallucinating 12% of the time.
What Traditional Feature Flags Actually Measure
Traditional feature flags answer one core question: did this change affect user behavior differently across cohorts? The implicit assumption is that the feature itself behaves consistently — the new checkout flow either shows the promo banner or it doesn't, and you're measuring whether the banner changes conversion.
The feature is deterministic. The only variable is user exposure. So a 10% rollout is statistically meaningful: you're comparing two populations experiencing two consistent, stable variants.
This model breaks completely when the feature itself is a source of variance.
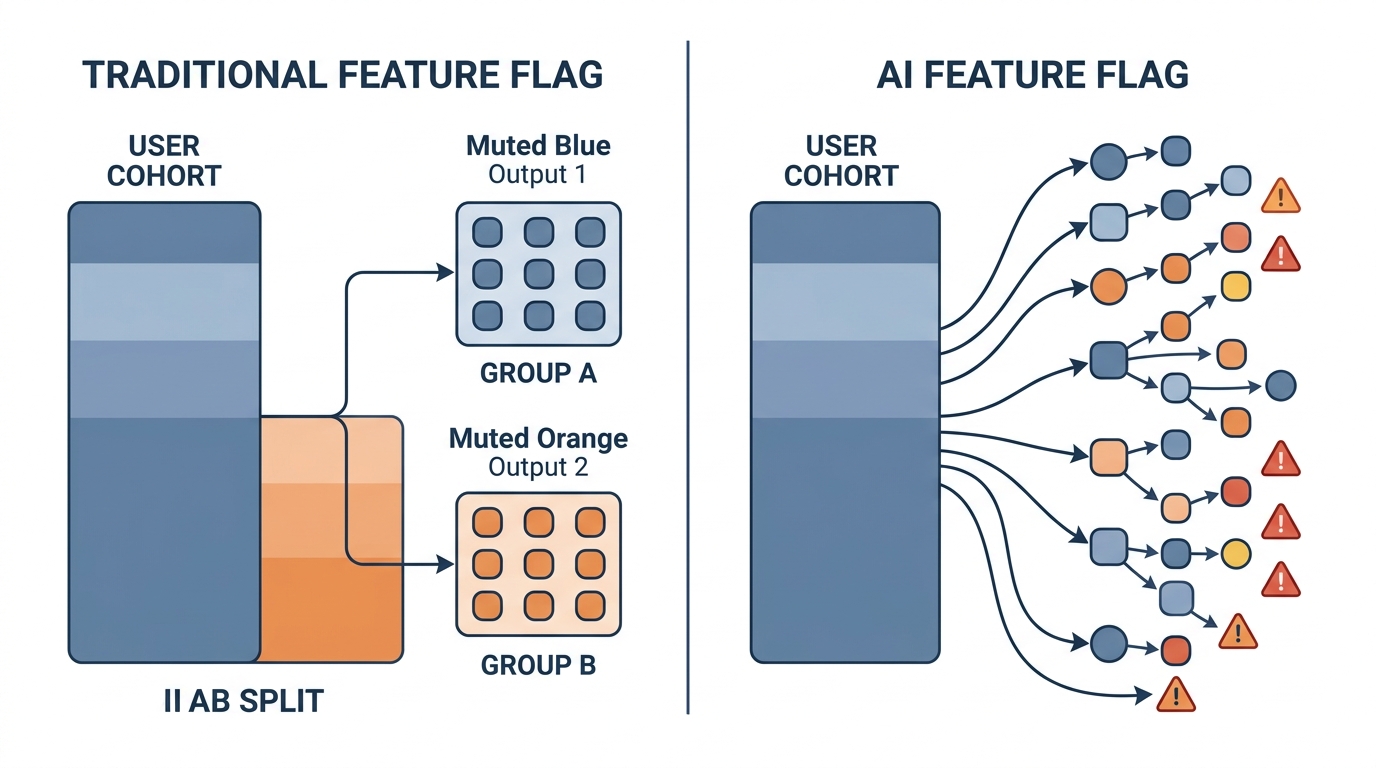
With an LLM feature, you have at minimum three independent sources of variance:
- Model behavior — temperature settings, sampling strategies, and model version updates all shift output distributions, sometimes silently
- Prompt sensitivity — small differences in user input phrasing can produce dramatically different outputs, even with identical system prompts
- Context variability — RAG-augmented features pull different retrieved chunks depending on the query, making each request compositionally unique
A 5% user rollout controls for none of this. You're measuring whether 5% of users had a good experience, not whether the model is producing good outputs. Those are different questions, and conflating them is where quality failures hide.
The Hallucination That Hides in Your Success Metrics
Here's a concrete example of how this plays out. Imagine you're shipping an AI feature that summarizes customer support tickets for your support team — pulling out key issue, priority, and any mentioned deadlines or SLAs.
You flag it to 10% of your support agents. Your metrics:
- Adoption: 78% of flagged agents used it at least once ✓
- Satisfaction score: 4.1/5 ✓
- Handle time: down 14% ✓
- Error rate: 0.2% (same as baseline) ✓
Everything looks good. You ship.
What your metrics didn't catch: in 12% of tickets mentioning dollar amounts, the model was confidently transposing figures — summarizing a $1,200 refund request as $12,000, or a 12-day SLA as 120 days. The agents weren't catching it because the summaries looked authoritative and they were under time pressure. The errors only surfaced when customers escalated.
Why didn't your 10% rollout catch this? Because:
- The failure mode was input-conditional — it only triggered on tickets with specific numeric patterns, which may have been underrepresented in your small cohort
- The output looked plausible — satisfaction scores measure perceived quality, not factual accuracy
- The agents didn't have a baseline — they couldn't compare the summary to ground truth unless they re-read the original ticket, defeating the purpose
This is the core danger: LLM outputs can be high-confidence and wrong simultaneously. Traditional success metrics aren't instrumented to detect this because they were never designed for a world where the feature itself lies.
Canary Deployments Need Variance Baselines, Not Just Conversion Comparisons
In traditional canary deployments, you're comparing aggregate metrics between your canary cohort and the control. The comparison is valid because both groups are experiencing stable, deterministic behavior.
For AI features, you need a different comparison axis: output variance over time against a fixed input baseline.
The idea is to maintain a set of canonical test inputs — a "golden set" — that you run against your model on every deployment, at every flag increment. These aren't user-facing; they're synthetic probes that let you measure whether the model's behavior has drifted from an established baseline.
What you're tracking per flag increment:
- Semantic consistency score — do outputs on identical inputs remain meaningfully similar across requests? (cosine similarity between embeddings is a practical proxy)
- Hallucination rate on verifiable claims — for any output that includes facts, dates, numbers, or named entities, what percentage can be verified against source material?
- Confidence calibration — when the model expresses certainty, is it actually correct more often than when it hedges?
- Output length and format drift — LLM outputs can shift in structure even when they're factually stable, which breaks downstream parsing
None of these require a large user cohort. You can run your golden set continuously with zero user exposure, before you ever flip a flag.
How to build a practical golden test set for your AI feature
A golden test set for an AI feature flag should include:
Coverage across input archetypes — identify the 5–8 distinct categories of inputs your feature will handle. For a summarization feature: short tickets, long tickets, tickets with numbers/dates, tickets in multiple languages, tickets with ambiguous pronouns, tickets with no clear resolution.
At least 10–15 examples per archetype — enough to measure variance within category, not just across categories.
Ground truth annotations — for each example, define what a "correct" output looks like. This doesn't have to be exhaustive; even binary pass/fail on specific claims ("does the summary correctly identify the ticket priority?") is valuable.
Adversarial examples — inputs specifically designed to probe known failure modes: very long inputs that might get truncated, inputs with contradictory information, inputs that include numbers or proper nouns that are easy to hallucinate.
Run this set on every prompt version change and every model update, before any user traffic hits the new variant. The results become your variance baseline.
The Right Flagging Primitive: Prompt Version × Quality Threshold
The practical implication of all this is that AI feature flags need a different primary dimension. Instead of flagging by user percentage, flag by prompt version + output quality threshold.
Here's what that looks like operationally:
Prompt version as a first-class flag dimension — every change to your system prompt, few-shot examples, or retrieval strategy gets a version identifier. Your flag controls which prompt version is active, not just whether the feature is on or off. This lets you roll back to a specific prompt state, not just to "the old feature."
Quality thresholds as hard stops — before incrementing user exposure (5% → 25% → 50%), your golden set must pass a quality threshold. If hallucination rate on verifiable claims exceeds 5%, the rollout pauses automatically, regardless of user satisfaction scores.
Variance bounds as a circuit breaker — track the standard deviation of your quality scores across the golden set. If variance spikes — even if mean quality looks acceptable — treat it as a signal that the model's behavior is becoming unpredictable. An AI feature with high average quality but high variance is a liability at scale.
Prompt Version + Quality Threshold Flagging
- Catches output quality failures before they reach users at scale
- Enables precise rollbacks to a specific prompt state, not just on/off
- Creates an audit trail of model behavior changes over time
- Decouples user exposure decisions from quality validation
Traditional User-Cohort Flagging Applied to AI
- User satisfaction scores mask factual accuracy failures
- No mechanism to detect hallucination rate drift
- Rollback reverts the whole feature, not a specific prompt version
- Small cohorts can't statistically surface rare but serious failure modes
Instrumenting for This Without Building a Research Lab
None of this requires a dedicated ML infrastructure team. The minimum viable instrumentation stack for variance-aware AI flagging:
Log every input-output pair — this is non-negotiable. You cannot debug quality failures retrospectively without the raw data. Store the full prompt (system + user), the model response, the model version, the prompt version, and a timestamp. Tools like Langfuse and Helicone make this straightforward without building custom pipelines.
Tag outputs by flag variant — your flag system should inject a variant identifier into every LLM call metadata. This lets you slice your quality dashboard by prompt version, which is the comparison that actually matters.
Build a lightweight quality dashboard — you don't need a sophisticated eval framework on day one. Even a simple dashboard tracking output length distribution, flagged keyword frequency (for known hallucination patterns), and golden set pass rates over time gives you the variance signal you're missing with pure user metrics.
Set hard-stop thresholds before you start the rollout — decide in advance: if hallucination rate on golden set exceeds X%, or if output variance exceeds Y standard deviations from baseline, the rollout pauses. Make this automatic, not a manual decision. Manual decisions get skipped under shipping pressure.
gpt-4o-2024-08-06 instead of gpt-4o) is a prerequisite for meaningful variance tracking. Floating aliases mean your "stable" feature can drift silently when OpenAI updates the underlying model.What This Means for Your Rollout Process
The operational change this requires is modest. The philosophical change is significant.
Traditional feature flagging treats the feature as a known quantity and measures user response. AI feature flagging has to treat the model's output distribution as the unknown quantity and measure that first, before measuring user response.
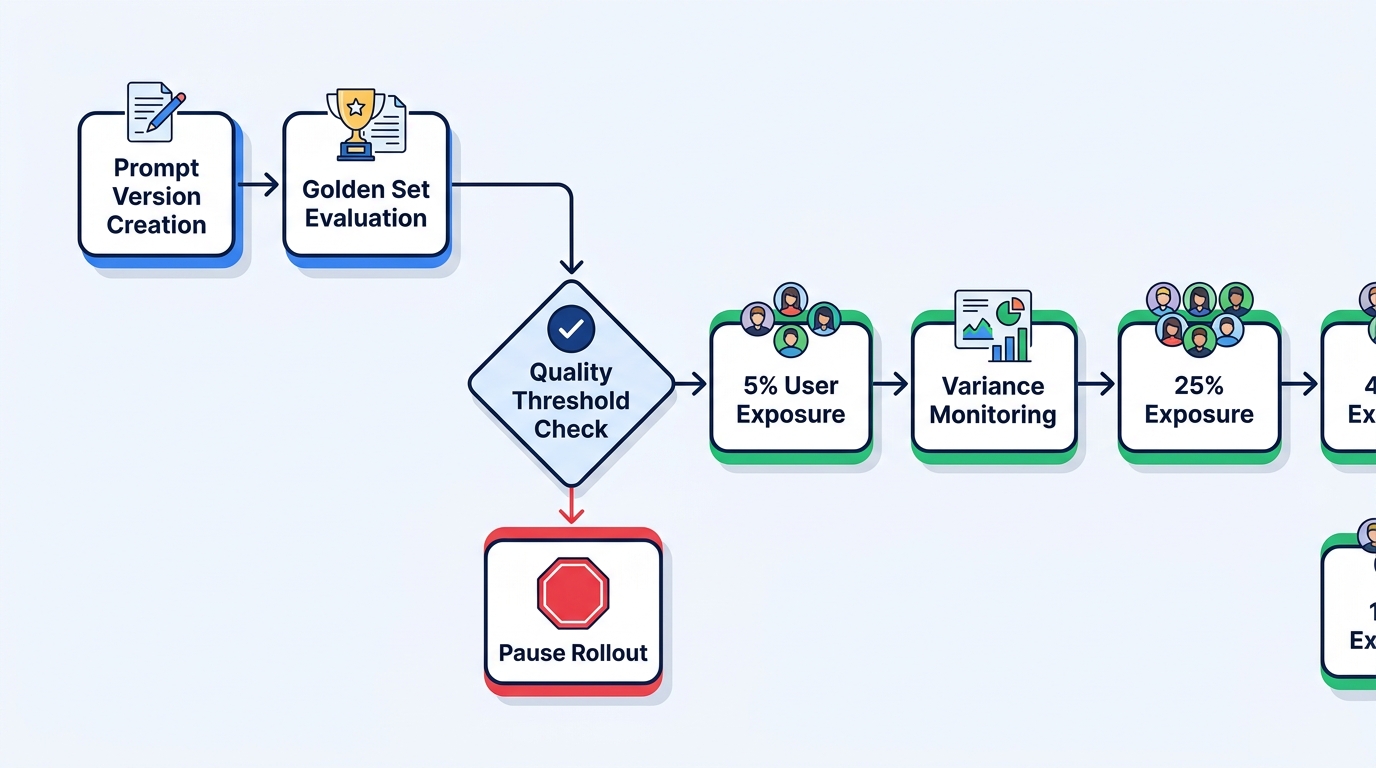
This means your rollout sequence changes:
- Define golden set and quality thresholds (before any code ships)
- Run golden set against new prompt version (zero user exposure)
- Validate variance is within acceptable bounds (not just mean quality)
- Gate 5% user exposure on golden set pass (not on a calendar date)
- Monitor variance continuously during exposure increment, not just aggregate metrics
- Automate rollback on threshold breach, with prompt version as the rollback target
The teams that get this right aren't necessarily the ones with the most sophisticated ML infrastructure. They're the ones that recognized early that shipping an LLM feature is more like deploying a probabilistic system than shipping a new UI component — and adjusted their quality gates accordingly.
The canary in the coal mine metaphor was always about catching silent failures before they become visible ones. For AI features, the canary needs to be your golden test set, not your first 5% of users.